
 Last modified:
Sunday, 16-Feb-2020 19:35:41 UTC. Maintained by: Elisa E. Beshero-Bondar
(eeb4 at psu.edu). Powered by firebellies. Last modified:
Sunday, 16-Feb-2020 19:35:41 UTC. Maintained by: Elisa E. Beshero-Bondar
(eeb4 at psu.edu). Powered by firebellies.
Last modified:
Sunday, 16-Feb-2020 19:35:41 UTC. Maintained by: Elisa E. Beshero-Bondar
(eeb4 at psu.edu). Powered by firebellies. Last modified:
Sunday, 16-Feb-2020 19:35:41 UTC. Maintained by: Elisa E. Beshero-Bondar
(eeb4 at psu.edu). Powered by firebellies.Remember how we’ve described XML as like “nested boxes” or a “tree”? (Review that, if you like, on our page explaining XML “So What Exactly is XML anyway?”) Think of a whole XML file as a big box, and nested inside it are smaller boxes. If we think of XML as a tree, we can consider the whole file as springing from one root, and branching out in complex ways.
XPath is a language that we write to select parts (or nodes) of an XML document, so we can pick out the pieces, remix them, add to them, count them, number them, etc. We write what’s called an XPath expression so a computer can follow the path we lay out to to certain parts of an XML document. The way we express this needs to be very precise, though often there are multiple ways of creating a path or identifying a location in a document.
Though we sometimes “do XPath” for its own sake while we’re coding our files, to help us find particular things, or check or count something, most often we use XPath expressions within XML-transformation languages, including XQuery (XML Query Language) and XSLT (eXtensible Stylesheet Language Transformations). XPath is a “helper” or ancillary language that’s necessary to work with these transformation languages, which allow us to remix, rewrite, extract pieces from, and add pieces to XML files. Before you can write these transformations, you need to learn XPath.
Think of our nested boxes in XML as made of nodes. A node is a position on the XML tree, and can be one of seven kinds:
document('URL')element(). Remember, this contains the
start and end tags and everything inside: from <element> . . .contents .
.</element> .attribute(). This contains an attribute
name and its value, as in item="beads" in the element <trade item="beads">. text() which is the text content within an
element. (We locate the text node in cases when we want to strip out elements and
preserve only the text. This is not to be confused with the string()
function which reaches deep into all nested elements to retrieve their text nodes.) comment() to retrieve XML commentsnamespace() to retrieve only XML code in
a specified namespace when these are mixed in a document containing, say, both HTML
and KML.processing-instruction().
This contains special processing code with syntax that starts with <?
and ends with >This link provides a handy picture of how element nodes and text nodes fit together in a "tree:" David Birnbaum’s XPath intro page on nodes.
We’ve shown you the Outline View in <oXygen/>, and it may be helpful to look at an outline of a file now, to explain how nodes relate to each other.
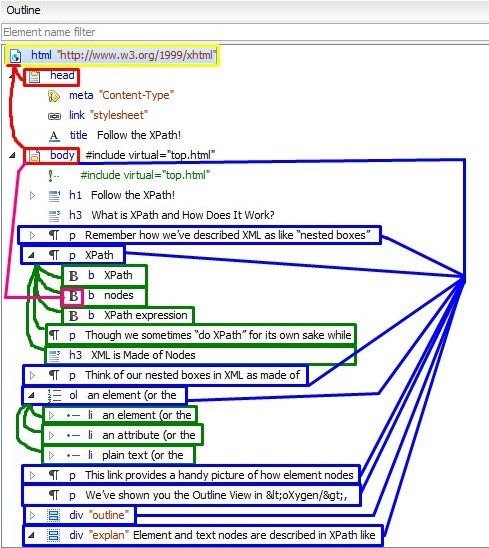
Element and text nodes are described in XPath like a big family of ancestors, descendents, parents, children, and siblings.
In the Outline view of this HTML file which we took from <oXygen/>, we’ve marked multiple levels of a family relationship: The yellow squared root node <html> is the original ancestor of all the descendents inside. The red squared nodes (the <head> and <body> elements) are the immediate children of the <html> root node. They are also siblings to each other.
What’s the relationship of the <b> node (squared off in pink) to the <body> node? It’s a grandchild, or a descendant. And it’s the child of the <p> element. See how that works?
The elements I’ve squared off in blue may help us to visualize siblings, all the
children of <body>. In XPath, we can distinguish
these siblings in relation to each other. The second element squared in blue, the
<p> element with the text “XPath”, is the
"following-sibling" to the <p> element
holding the text "Remember how we've described XML..." And we can say that the
preceding-sibling to the <ol> element is
the <p> element, which holds the text, “Think of our
nested boxes in XML...”
What we’ve just been describing about family relationships is closely connected to axes in XPath. XPath’s default is to locate the child of the current context node (or the current position designated in the XML file). Basically, when you designate an axis in an XPath expression, you’re indicating the direction you want your path expression to go: Do you want it to look up to a parent or ancestor? Or down to a child or descendent?
| ancestor:: | The ancestor axis sends you to parents and above, all the way up to the root node. |
| parent:: or . . | The parent axis sends you up a short distance, to the immediate parent of the context node. |
| child:: or / | The child axis (which is the default) sends you down to the immediate child of the context node. |
| descendant:: or // | The descendant axis sends you down to the children and their children, and their children’s children, etc. |
| preceding-sibling:: | The preceding-sibling axis sends you to the leftto the sequence of siblings that come before the context node (the big brothers and sisters, or earliest children of a parent). |
| following-sibling:: | The following-sibling axis sends you to the rightto the sequence of siblings that come after the context node (the little brothers and sisters, or younger children of a parent. |
| preceding:: | The preceding:: axis sends you on a longer path than the
preceding::sibling axis, as it looks for any nodes that
precede the current context node in the document order, which includes the
preceding siblings as well as the preceding nodes that are not siblings. We
commonly use this axis (or its mirror-image, the following:: axis)
when we are looking for preceding instances of a particular element that are not
siblings, but nested inside nodes that appear earlier in a document, like looking
for all the preceding paragraphs, or lines of a poem when these are nested inside
earlier div elements or earlier line-groups. If you think about this axis in terms
of the nodes on the XML tree, ancestors of an element are NOT on the preceding
axis, even though they begin before the current context! That is because the
ancestor node is still open around the current context node while you are
invoking it. The ancestor of the current context doesn't precede it because it is
currently containing it. |
| following:: | The following:: axis is the mirror-image of the
preceding:: axis, so the following:: axis sends you
to all the nodes that follow the current context in the document order, which
includes the following sibilings as well as the following nodes that are not
siblings. |
| self:: or . | There’s a selfaxis designating the current context node, which is useful sometimes when need to indicate the current location in a path. |
| attribute:: or @ | One last axis that’s sort of in its own parallel universe: the attribute (@) axis! You can follow one of the paths up or down or left or right among elements, and if you want to locate attributes in particular, or want to locate only the elements with a particular attribute or attribute value, you move to the @ axis. |
When we write path expressions, we indicate the axis, and we could indicate the name of an element we’re searching for, or another node specifier like the text node or text(). There’s a longhand form for specifying axes, and sometimes that longhand comes up in the XPath window in <oXygen/>, so it can be handy to know what these are and what they mean. Use whatever form of these makes the most sense to you as you’re writing your XPath expressions.
So you want to start writing an XPath expression already! Here we go. Use the XPath window in the upper left of your <oXygen/> screen, and select XPath 3.1 in the drop-down menu to its left. An XPath expression is a kind of journey, and it begins by figuring out where you are (what’s your context node?) and taking a step along an axis direction.
When we start writing XPath expressions, we usually begin from the document
node at the top of the tree. (The root element is actually the child in XPath terms of that document node.) Many of our path expressions will begin with a
double slash: //, and at the start of an XPath expression that always means,
start at the document node and search through all XML nodes that descend from here (on the descendant:: axis all the way through the XML tree hierarchy.
If we start our XPath expression with the double slash, we indicate we are
beginning at the top-level document node and working our way down one or more levels to whatever node we indicate next:
//body/div/p
This expression means, start at the beginning node of the document and look
for the body element anywhere below. Next, switch to the child:: axis, and take
one step to find the immediate children of body–the sequence of div
elements (however many there are). Then find all p elements that are the
immediate children of all the div elements. XPath expressions are designed to return a sequence of results, whether that's a sequence of zero, one, or many items.
If the div elements just do not have any child
p elements, we will not see an error message from XPath. We will just
return a sequence of zero results.
What if we want to return all the elements at a particular level, regardless of what they are? Here’s where we use the asterisk: *. Examples:
//body/div/*
//body/div//*
parent::*
self::*
Notice how these work: We say, in the first one, start from the document (root) node,
and go down to find the body element, then all the div elements that are children
of body, and then please return all the elements that are the immediate
children of div. How’s the second one different from the first? Notice that we
take a longer step down with that double slash: This says, with all those div
elements that are children of body, please look down the descendent axis and return all
the elements that are either the children or the descendents of div.
With
the last two, notice we designate the axis first. The parent::*
will return the name of the parent element for the current context node,
whatever it is. (“Who’s my mommy?“) The last one I wrote for the sake of writing it:
What if we were somehow lost in an XML file and just wanted to return the name and
location of the current context node: (“Where am I??” or “Who am I?”). We do not often have to reference the self::* axis,
but I just invoked it while typing inside the p element forming this paragraph, and returned the entire element node in which I am currently typing this.
Now, a single slash, /, typically indicates taking a step in a path expression, that is, “take one step down and find the immediate children of the context node.” When we’re writing XQuery and XSLT we’ll find ourselves writing XPath expressions from specific points inside a document (not necessarily from the root or document node up at the top), so in those cases we might actually begin an expression like this:
p/span
This means, starting from the current context node, look for the immediate children named p, and then go down and find all the immediate children of p named span.
So how do we work with attributes? They have their own @ axis. Here are some examples of how you can access the attribute axis and what you might find:
//@id
//div/@id
The parents are attributes are technically elements, so very frequently we climb down (or up) an axis to locate a parent element, and then shift over to the attribute axis with the /@, as we did in the second example here. Notice with the first example, though, that this actually starts from the document (root) node, and hunts through the whole document looking for all instances of the @id inside elements wherever it may turn up. If you download this html file that you’re reading, open it in <oXygen/> and run that XPath, click on the results in the bottom view window, and they’ll highlight just the attribute portions of their elements.
Predicates in XPath are filtering tools. When we write these, we want to keep in mind the structure of the document, and the direction that the computer processor “looks” as it’s following your XPath expression. David Birnbaum gives a good flowchart explanation of how this works on the “Predicates” section of his XPath site. When you write a predicate, you indicate how to select a specific thing out of a lineup, a particular paragraph based on its position, for example. You write a predicate using square brackets:
//div/p[1]
//div[@id="space"]/p[1]
So, say we have multiple div elements, each of which has
multiple p children. The first expression returns, for each
div in turn, its first
p child. In my document, I have two divs with p children, so
this XPath returns 2 results, the first paragraph only in each of these
divs.
The second is a little more complex: Can you work it out? Here we use
predicates in two steps of our XPath expression, to streamline results at each level:
First, we say, look for ONLY the div element with the @id="space". We filter out all
of the other divs which have different @id attribute values, then, and we ONLY
look inside this one div that has this distinguishing characteristic. Then, we step down
and find its first p child. Make sense?
Now, you can actually set multiple predicates [][] right next to each other in an XPath
expression. Here’s an example of when you might need to do this: Say you have a file
divided up into multiple sections using div elements. Let’s
say that several of these div elements are designated with
@type, as in <div
type="poem"> to indicate a particular kind of content inside. You may have
other div elements designated as @type="preface" and @type="acknowledgments". So
this file is basically a “book” of poems with some accompanying material, and the div elements separate each poem from the others. Now, let’s say
you want to find your way with XPath to the fifth poem in the file. Here’s how
you’d do that by making two predicates side by side:
//div[@type="poem"][5]
See how this works? First you say, find me the div elements filtered by @type="poem", and then filter those results to give me just the fifth one in the sequence.
Functions let us do some processing of the things we locate with XPath expressions. What if you don’t want to return all the p elements inside a div, and you just want to count them all? That’s when we use a function called count(). You put in parentheses the nodes you want to count, and this can work in lots of ways:
count(//@id)
//div/count(p)
count(//div/p)
//div[@id="space"]/count(p)
In the first of these, I’ve written an expression that says, "Count the number of times
the @id attribute is used in this file, starting from the root
(document) node. (When I run it here in <oXygen/> as I’m writing this document,
the answer is 3 (as I see in the bottom window).
The second expression,
//div/count(p), says, start from the root node, go down to
ALL the div elements in the file, and then count the p elements in EACH div, one by one.
My bottom view screen in <oXygen/> gives me a set of three results, with a count
for each div in turn. That can be handy!
But what if we want to find out
how many p elements there are total under ALL the divs? That’s what the third
expression, count(//div/p) does: It gives just ONE result, and
it’s a count of ALL the p elements in ALL the divs, without differentiating them div by
div by div. Let’s think about why this gives a different result from the previous
example: This has everything to do with where you place the count function! When you
place the count at the end, and don’t include the div element in the parentheses, you
effectively step down the tree to each div, and THEN do a count of the p elements inside
each. By contrast, when you say count(//div/p), the computer
postpones the counting until it’s found all the p’s everywhere that are children of
divs. The count function says, “Hey! round up ALL the p’s that are children of divs, and
count those.”
Can you figure out what the last expression is counting? //div[@id="space"]/count(p)
This combines a predicate with a function! So you indicate that you want to
start with only one div, the one with the @id="space" . Then you count the number of p
elements in that div.
Following the introduction of XPath 3.0 (and currently in XPath 3.1), we have an alternative syntax for applying functions using simple map and the arrow operator. We find these new notations a little easier to read and write, so we have prepared a short tutorial on how to use them on our DHClass-Hub and now use these notations in class.
You can actually put functions inside predicates in XPath as a way to filter your results! Here’s an example: Say we want to find any and all div elements that have just one p child? We’d write that expression this way:
//div[count(p) = 1]
Here’s another example. What if want to return an div element that doesn’t have ANY p elements? Here we’d use a predicate again, and this time use a function called not()
//div[not(p)]
About these examples: Notice that when you put a function in an XPath predicate, you don’t have to indicate that you’re stepping down a tree to get the child element. The default expectation when we don’t give an axis is that we’re stepping down to the immediate child.
Quite often in writing XPath, we’re trying to find something in terms of its position.
We’ve given you examples of predicates that return a specific numerical position, as in
the first or fifth paragraph or div element, using [1] or [5]. But what if you don’t
have an exact position, but know you want to return, say, the first 10 of a particular
element? Here’s where we can use the position() function.
//div[@type="poem"][position() < 10]
This retrieves the first 10 <div
type="poem"> elements in an XML collection of poems chunked in divs. The
predicate expressions work to filter by grabbing all the appropriate “poem” divs whose
position is 10 or under. Note that nothing goes inside the parentheses for position(). Context functions like this keep the
parentheses open. (Basically, position() and last() are written differently from the mathematical functions
like count(), where we indicate a particular thing to be counted inside the
parentheses.)
Here’s another useful positional function: last()
As you might expect, last() returns the last of a thing you’ve
designated. This is another positional function frequently used in predicates. So, where
//p[1] returns the first <p> element in the document,
//p[last()] returns the last, wherever it is, and it’s
handy because we usually don’t know how many p elements (or paragraphs) there are in a
big file! Again, note that nothing goes inside the parentheses for this positional
function.
XPath has a little over 100 different functions to choose from, but in most project scenarios, you really only need to work with a handful, which you’ll get to know pretty well. (One of our favorites is distinct-values(), which we’ll show you. We use distinct-values to eliminate repetition in a list of results, so we get only the distinctly different things, like the names of elements we’ve used, for example. Don’t try to memorize these, but you’ll need to look them up periodically and find one to use. Here are some useful XPath function lists, with explanations of what the functions do and how they work:
Here is a handy quick
review of terms and symbols. Check out the combination of predicates and
functions on that page in the expression with string-length() just above the review: See if you
can understand it.
We often write XPath predicates to find out where a count() of something is
no higher than X number, or where an attribute value in one position (say
//sp[@who="#NelsonNell"] is equal to a value in another position (say
//persName[@ref="#NelsonNell"] in our XML documents. To express
conditions of comparison, where one value compares a certain way with another value, we
use comparison operators. XPath can express two types of comparison:
value comparison and general comparison. We reproduce here
Obdurodon’s explanation of value comparison and general comparison with examples of
each. The next sections on value comparison and general comparison are quoted from the
indispensable resource, The Xpath
functions we use the most.
The value comparison operators are:
Value comparison can be used only to compare exactly one item to exactly one other item.
For example, to create a predicate that will filter <sp> elements to
keep only those where the value of the associated @who attribute is equal
to the string hamlet
, we can write:
//sp[@who eq 'hamlet']
Since each <sp> has exactly one @who attribute and since
we are comparing it to a single string, the test will return True or False for each
<sp> in the document. Because the exactly one item
can be
an empty sequence (technically no items), the test will also work (and return False)
when an <sp> element has no @who attribute. It is,
however, an error if either side of the comparison contains a sequence of more than one
item.
Value comparison is often used for numerical values. To keep all of the speeches
(<sp> elements) with more than 8 line (<l>)
descendants, we can write:
//sp[count(descendant::l) gt 8]
In the preceding example, the output of the count() function is a single
item, an integer, and it is being compared to another single item, the integer value
8.
The general comparison operators are:
While value comparison operators can compare only one thing on the left to one thing on the right, general comparison operators can have one or more items on either side of the comparison (also zero items, since the empty sequence is also allowed). For example:
//sp[@who = ('hamlet', 'ophelia')]
will retain all <sp> elements where the @who attribute
is equal to either
hamlet
or ophelia
. This makes general comparison a convenient alternative
to a complex predicate like:
//sp[@who eq 'hamlet' or @who eq 'ophelia']
In comparisons with exactly one item on either side of the comparison operator, value comparison and general comparison are equivalent.
One possibly surprising feature of general comparison is the way it behaves with negation. Consider:
This does not find all speeches by anyone other than Hamlet or Ophelia! It
finds all speeches where the @who attribute is not equal to any
one of the individual items in the sequence on the right. This means that it
finds all speeches without exception, since the ones by Hamlet are not by Ophelia (the
test succeeds because @who is not equal to ophelia
in situations
where it is equal to hamlet
) and vice versa.
So how do you find all speeches by anyone other than Hamlet or Ophelia? Try:
//sp[not(@who = ('hamlet', 'ophelia'))]
The preceding predicate says that we want to keep all speeches where it is not the case
that the @who attribute is equal to either hamlet
or
ophelia
.
| Description | Value | General |
|---|---|---|
| Equal to | eq | = |
| Not equal to | ne | != |
| Greater than | gt | > (>) |
| Greater than or equal to (not less than) |
ge | >= (>=) |
| Less than | lt | < (<) |
| Less than or equal to (not greater than) |
le | <= (<=) |
For more guidance on how to write XPath expressions with functions and predicates, please see:
The XPath Functions we use most: We find ourselves consulting this site nearly every day for a handy listing and explanation of functions and comparison operators.
An Intro to XPath Functions: our DHClass-Hub wiki tutorial on how to write XPath functions, considering why some of them surround whole expressions and some are positioned at the ends of nodes, made from our class prep notes on the DHClass-Hub